



Monta tu laboratorio de IA para hacking: orquesta ataques reales con agentes autónomos y exprime tu GPU en local
por Raúl UnzuéLaboratorio Ciberseguridad con Modelos LLM Locales
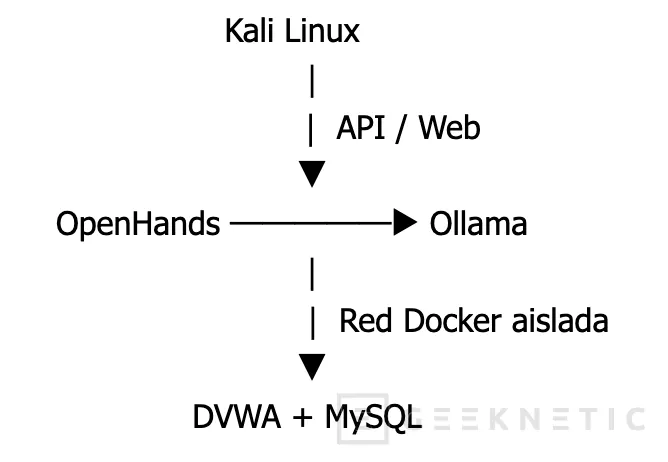
Este laboratorio nace con un objetivo muy concreto, construir un entorno controlado donde combinar modelos LLM locales, agentes autónomos y herramientas clásicas de pentesting dentro de una arquitectura aislada y reproducible.
La idea no es únicamente desplegar un modelo de IA en un servidor con GPU, sino integrar toda la cadena operativa necesaria para experimentar con automatización ofensiva real, análisis de resultados, generación contextual de comandos, ejecución mediante agentes y validación contra objetivos vulnerables contenidos dentro de una red segmentada.
La infraestructura utilizada en esta guía está basada en un Ubuntu Server con GPU NVIDIA dedicado a inferencia local mediante Ollama, una Raspberry Pi ejecutando Kali Linux como nodo atacante y una red Docker aislada donde se despliegan los objetivos vulnerables. Sobre esta base se añade OpenHands como agente capaz de interactuar con el sistema y ejecutar acciones reales utilizando modelos locales.
A diferencia de muchos laboratorios orientados únicamente a pruebas funcionales, aquí se presta especial atención al aislamiento de red, las reglas de firewall, la segmentación entre contenedores y la limitación de exposición de servicios. El objetivo es poder experimentar con automatización ofensiva asistida por IA sin comprometer el resto de la red doméstica o corporativa.
Durante la guía se construirá paso a paso un entorno completo capaz de:
- Ejecutar inferencia local acelerada por GPU.
- Permitir interacción remota desde Kali Linux.
- Desplegar agentes autónomos conectados a modelos LLM.
- Aislar objetivos vulnerables mediante redes Docker dedicadas.
- Aplicar hardening básico sobre Ubuntu y Docker.
- Automatizar pruebas ofensivas dentro de un entorno contenido.
El resultado final será un laboratorio reproducible y extensible, preparado tanto para investigación como para formación avanzada en IA aplicada a ciberseguridad ofensiva.
Arquitectura del Laboratorio
| Sistema | Función |
|---|---|
| Ubuntu Server + NVIDIA GPU | Inferencia local y orquestación |
| Ollama | Modelos LLM locales |
| OpenHands | Agente autónomo |
| Raspberry Pi + Kali | Nodo atacante |
| Docker lab-net | Red aislada vulnerable |
| DVWA | Objetivo vulnerable |
| Equipo / Servicio | IP / Red | Puerto | Acceso permitido |
|---|---|---|---|
| Ubuntu Server (host) | 192.168.2.196 | — | LAN local |
| SSH Ubuntu | 192.168.2.196 | 22 | Solo 192.168.2.0/24 |
| Ollama (LLM inference) | 192.168.2.196 | 11434 | Toda la LAN 192.168.2.0/24 |
| OpenHands (agente) | 192.168.2.196 | 3000 | Solo 192.168.2.130 (Kali) |
| DVWA (víctima) ** | 10.10.10.10 (lab-net) | 80 interno | Sin acceso externo a LAN |
| Raspberry Pi (Kali) | 192.168.2.130 | — | Atacante del lab |
| lab-net (bridge Docker) | 10.10.10.0/24 | — | Aislada, solo contenedores |
** DVWA (Damn Vulnerable Web Application) es una aplicación web escrita en PHP y MySQL diseñada para ser vulnerable a los ciberataques más comunes.
Flujo Lógico
Crear Red Docker Aislada
Partimos de tener docker instalado en Ubuntu Server. Si has dejado la instalación por defecto de Docker, dispondrás de una red "docker0" con rango de IP´s 172.17.0.1/16:
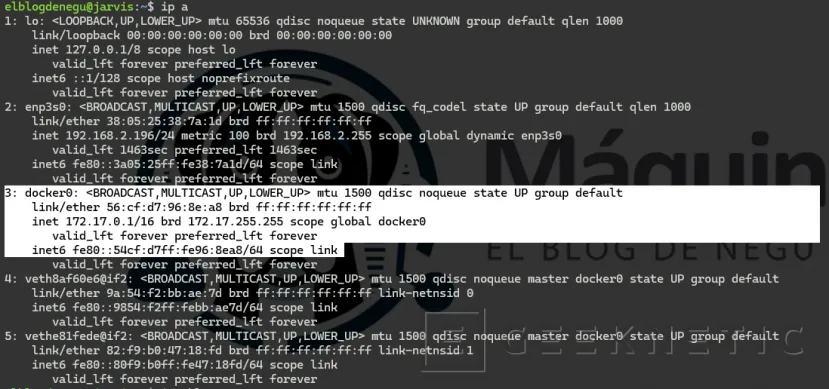
La red por defecto 172.17.0.0/16 tiene un problema para este caso, cualquier contenedor que arranques sin especificar red entra en ella y puede comunicarse libremente. Para el lab queremos una red dedicada con subred propia, control de IPs y sin acceso al exterior salvo lo que explícitamente permitamos.
Crear la red bridge del laboratorio
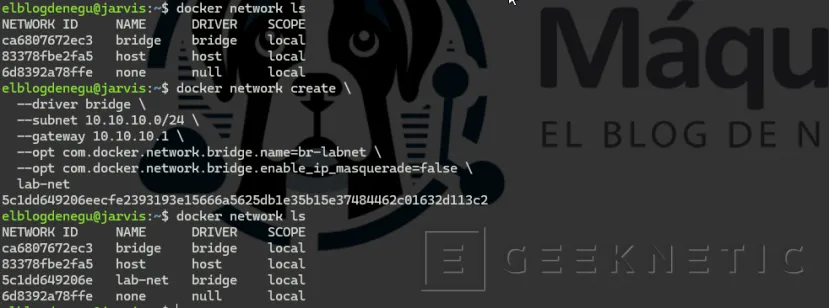
Lanzamos el siguiente comando para crear nuestra red Docker aislada:
docker network create \ --driver bridge \ --subnet 10.10.10.0/24 \
--gateway 10.10.10.1 \ --opt com.docker.network.bridge.name=br-labnet \
--opt com.docker.network.bridge.enable_ip_masquerade=false \ lab-netLa opción enable_ip_masquerade=false desactiva el NAT automático de Docker para esta red, lo que impide que los contenedores del lab inicien conexiones hacia Internet o hacia la LAN por su cuenta.
Verificar que la red existe y tiene la configuración correcta
Una vez creada, revisamos que está bien configurada con el comando:
docker network inspect lab-net | grep -A5 '"IPAM"'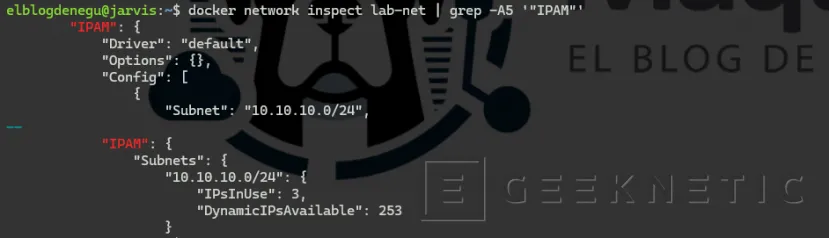
También se puede lanzar un docker network ls :
Bloquea el reenvío desde lab-net hacia la LAN a nivel de iptables / UFW
Docker manipula iptables directamente. Para evitar que los contenedores alcancen la LAN, añade una regla que bloquee el reenvío desde la interfaz del bridge de lab-net:
# Bloquea tráfico de salida de lab-net hacia la LAN física
iptables -I DOCKER-USER -i br-labnet -o enp3s0 -j DROP# Si usas UFW
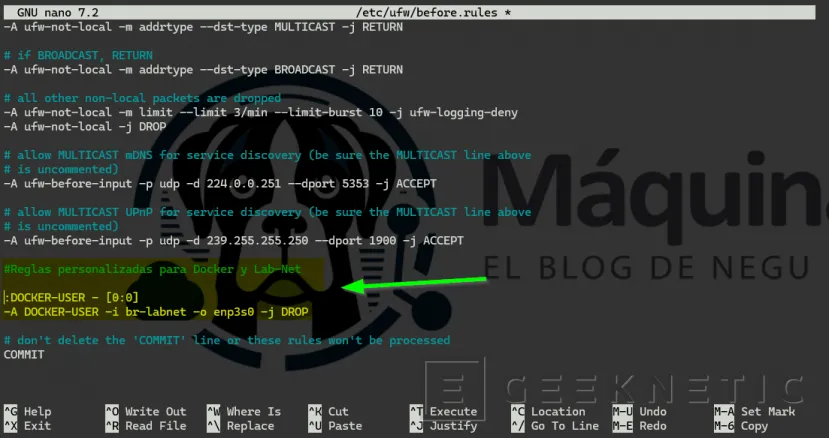
sudo nano /etc/ufw/before.rules
# Ve al final del archivo. Justo después de la última línea que dice COMMIT, añade el siguiente bloque de código:
#Reglas personalizadas para Docker y Lab-Net: *filter
:DOCKER-USER - [0:0] -A DOCKER-USER -i br-labnet -o enp3s0 -j DROP
COMMIT # Recargamos ufw sudo ufw reload
# Si tu interfaz de red se llama diferente, compruébalo:ip route | grep default
# Sustituye ens3 por tu interfaz (eth0, enp3s0, etc.)
![]()
Para hacer las reglas persistentes:
apt install iptables-persistent -ynetfilter-persistent saveO si usas UFW recargamos:
Hardening: Reglas Cortafuegos UFW
Las reglas de UFW NO afectan a las comunicaciones entre contenedores Docker de la misma red (esas van por el bridge). Como en nuestro laboratorio va a intervenir una máquina de la LAN con los contenedores Docker, deberemos ser lo más restrictivos con el tráfico y los accesos. Para ello vamos a hacer hardening de las reglas básicas de UFW.
Antes de comenzar a activar reglas, deberemos asegurarnos acceso físico o vía consola al Ubuntu, para no quedarnos aislados en el proceso.
Política por defecto: Denegar todo el tráfico entrante
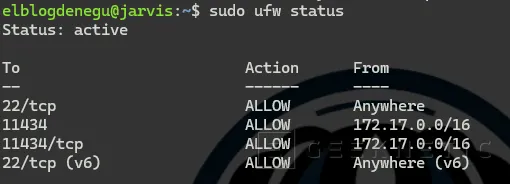
Antes de aplicar estas reglas, revisar que tenéis una regla mínimo para SSH:
Reglas por defecto a aplicar:
sudo ufw default deny incomingsudo ufw default allow outgoing
sudo ufw default deny forward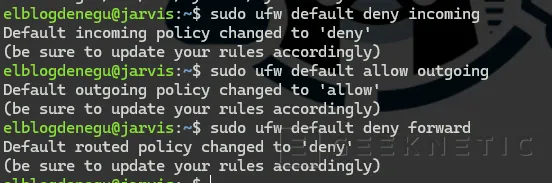
SSH: Solo desde la LAN local
sudo ufw allow from 192.168.2.0/24 to any port 22 proto tcp comment 'SSH desde LAN'![]()
Ollama (11434): Accesible desde toda la LAN
Esto te permite consultar Ollama desde cualquier máquina del lab, no solo desde Kali. Si en el futuro quieres restringirlo solo a Kali, cambia la subred por 192.168.2.130.
sudo ufw allow from 192.168.2.0/24 to any port 11434 proto tcp comment 'Ollama → LAN local'OpenHands (3000): Solo desde Kali
sudo ufw allow from 192.168.2.130 to any port 3000 proto tcp comment 'OpenHands → solo Kali'![]()
Si quieres acceder a la interfaz de OpenHands también desde tu máquina de gestión (por ejemplo para supervisar lo que hace el agente), añade otra regla con esa IP:
sudo ufw allow from 192.168.2.XXX to any port 3000 proto tcp comment 'OpenHands → gestion'![]()
DVWA (8080): BLOQUEADO desde el exterior
DVWA no vinculará el puerto 8080 a ninguna interfaz física (lo verás en el paso de despliegue). Aun así, añadimos la regla de denegación explícita como capa adicional:
sudo ufw deny from any to any port 8080 proto tcp comment 'DVWA bloqueado - solo lab-net'
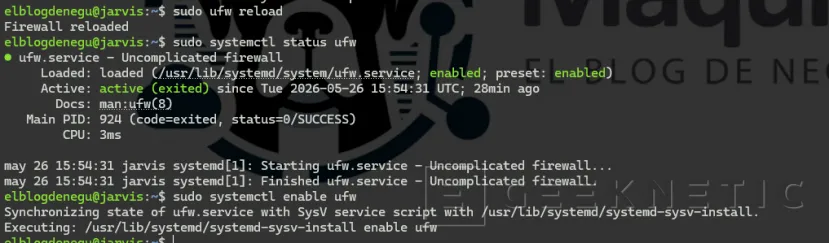
Activa UFW y verifica las reglas
Activamos el firewall UFW:

Comprueba el estado con numeración para verlo más claro:
sudo ufw status numberedDeberías ver algo parecido a esto:
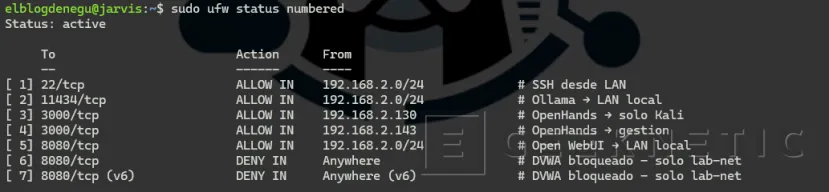
UFW y Docker no se llevan bien por defecto. Docker añade sus propias reglas en iptables que pueden saltarse las de UFW para puertos vinculados en 0.0.0.0. Por eso DVWA no va a vincular ningún puerto externo. Para los demás servicios que sí exponemos (Ollama, OpenHands), UFW funciona correctamente porque Ollama corre nativo y OpenHands está en --network host o con bind explícito.
Despliega Ollama con GPU: Inferencia Local sin Salir a Internet
Ollama corre nativo en el Ubuntu (no en Docker) para aprovechar directamente la GPU sin capas adicionales. Necesitamos que escuche en la IP física del servidor, no solo en localhost, para que Kali pueda consultarlo.
Instalar Ollama en Ubuntu Server
curl -fsSL https://ollama.com/install.sh | sh# Verifica que detecta la GPU:
ollama run qwen2.5-coder:7b# En otra terminal:
nvidia-smi # debe mostrar carga en GPU durante la inferencia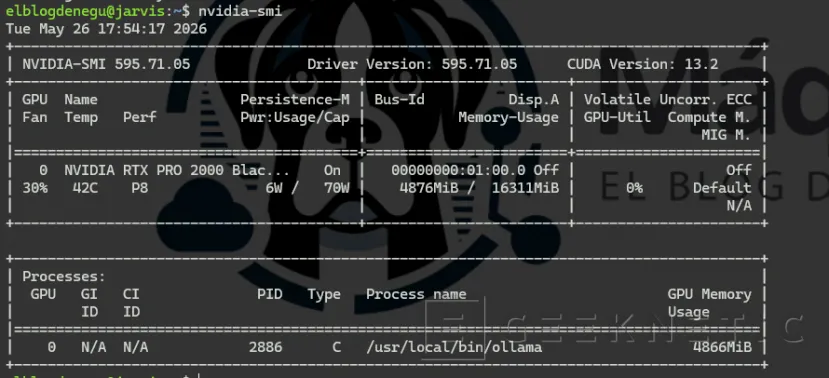
Configura Ollama para escuchar en la IP del servidor
Editamos y añadimos:
sudo systemctl edit ollama[Service]Environment="OLLAMA_HOST=192.168.2.196:11434"Y reiniciamos y verificamos:
sudo systemctl daemon-reloadsudo systemctl restart ollama
# Verifica que escucha en la IP correcta:ss -tlnp | grep 11434
# Debe mostrar: 192.168.2.196:11434Test de conectividad desde Kali
Si la respuesta llega correctamente, Ollama está accesible desde Kali y UFW está bien configurado.
curl http://192.168.2.196:11434/api/tags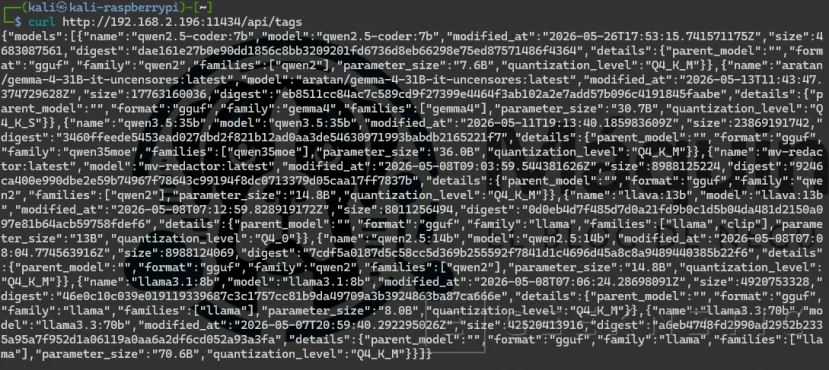
Descarga modelos optimizados para análisis de seguridad
# Modelo principal: bueno para generar comandos y analizar outputs de herramientas
ollama pull qwen2.5-coder:7b
# Alternativa con más contexto (si tu GPU tiene VRAM suficiente):
ollama pull llama3.1:8b
# Modelo ligero para la Raspberry si quieres ejecutar algo local en Kali:
# (en la Raspberry, no en el Ubuntu)# ollama pull qwen2.5:3b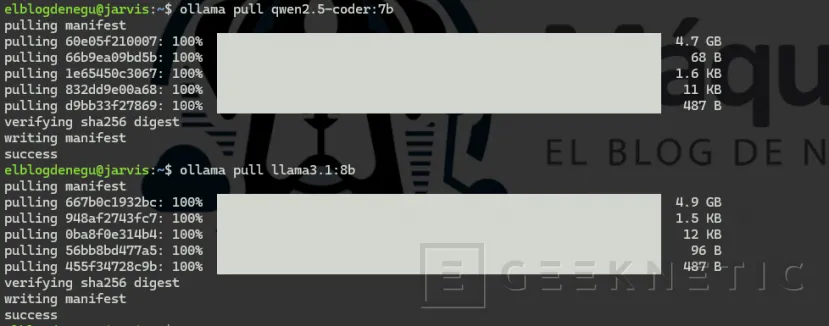
Instalar OpenHands y Conexión con Ollama
OpenHands es el agente que ejecuta comandos reales. Corre en Docker y se conecta a Ollama en el mismo servidor. Como necesita acceso a Docker (para lanzar su sandbox) y queremos que su interfaz web sea accesible desde Kali, lo arrancamos con el socket de Docker montado y el puerto 3000 enlazado a la IP del servidor.
Arranca OpenHands con bind a la IP del servidor
El bind 192.168.2.196:3000:3000 hace que el puerto 3000 solo escuche en la IP física del servidor, no en todas las interfaces. Combinado con UFW, solo Kali puede acceder.
docker run -d \ --name openhands \ --restart unless-stopped \
-e SANDBOX_RUNTIME_CONTAINER_IMAGE=ghcr.io/openhands/runtime:latest-nikolaik \
-e LOG_ALL_EVENTS=true \ -e LLM_MODEL=ollama/qwen2.5-coder:7b \
-e LLM_BASE_URL=http://host.docker.internal:11434 \ -e LLM_API_KEY=ollama \
-v /var/run/docker.sock:/var/run/docker.sock \ -v ~/.openhands:/.openhands \
-p 192.168.2.196:3000:3000 \ --add-host host.docker.internal:host-gateway \
ghcr.io/openhands/openhands:latest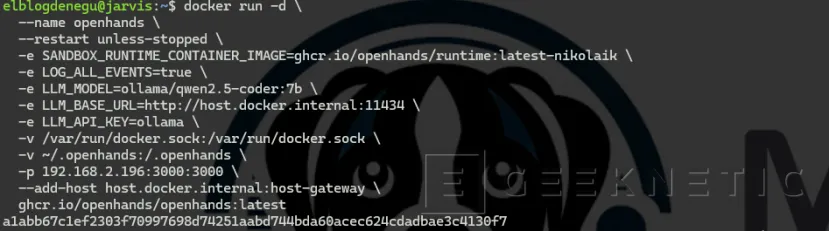
Conecta OpenHands con Ollama desde la interfaz web
Abre desde Kali:
firefox http://192.168.2.196:3000# o desde terminal Kali:
curl -s http://192.168.2.196:3000
host.docker.internal resuelve a la IP del host (192.168.2.196) desde dentro del contenedor gracias al flag --add-host. Así OpenHands llega a Ollama sin necesidad de usar la IP física.
Verificar que el agente puede ejecutar comandos
Verificamos que está corriendo:
docker ps | grep openhands
Verificamos que Ollama es accesible desde dentro del contenedor:
docker exec openhands curl -s http://host.docker.internal:11434/api/tags | python3 -m json.tool | grep '"name"'
Verificamos que el modelo está configurado correctamente:
docker exec openhands env | grep LLM
Mandamos una tarea de prueba al agente desde Kali, primero sacamos el ID que usaremos:
curl -s -X POST "http://192.168.2.196:39261/api/conversations" \
-H "X-Session-API-Key: BYWN2pGrif9riXaTG53weHlrSCbbJeGUeccwtmDjs3V" \
-H "Content-Type: application/json" \ -d '{ "workspace": {
"working_dir": "/workspace/project", "kind": "LocalWorkspace" },
"initial_message": { "content": [
{"text": "Ejecuta el comando hostname && id && ip addr show en la terminal y muéstrame la salida completa"}
] }, "agent": { "llm": {
"model": "ollama/qwen2.5-coder:7b", "api_key": "ollama",
"base_url": "http://host.docker.internal:11434" }, "tools": [
{"name": "terminal"}, {"name": "file_editor"} ],
"kind": "Agent" } }' | python3 -m json.tool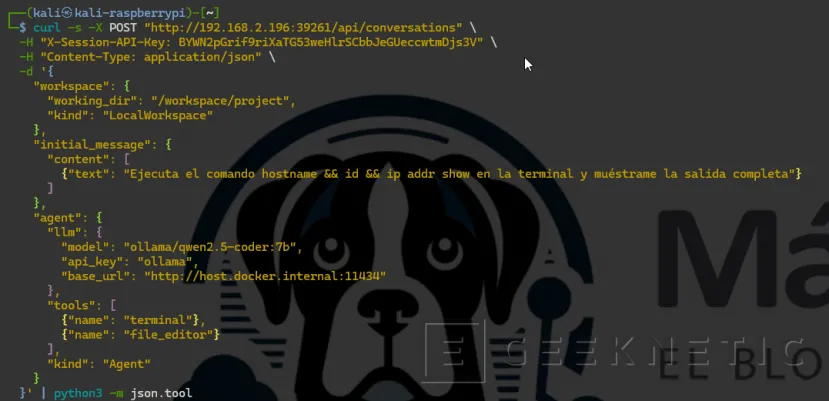
Los paths reales los podéis sacar de la siguiente forma:
curl -s http://192.168.2.196:3000/openapi.json | python3 -c "import json,sys
data=json.load(sys.stdin)for path in data.get('paths',{}).keys(): print(path)
"Una vez creada la conversación con éxito, arrancamos el agente:
curl -s -X POST "http://192.168.2.196:39261/api/conversations/159e8bfd-230a-401e-b6e9-42d3170e35f7/run" \
-H "X-Session-API-Key: BYWN2pGrif9riXaTG53weHlrSCbbJeGUeccwtmDjs3V" \
-H "Content-Type: application/json" \ | python3 -m json.tool
Esperamos 30 segundos y consultamos los eventos:
sleep 30 && curl -s "http://192.168.2.196:39261/api/conversations/159e8bfd-230a-401e-b6e9-42d3170e35f7/events/search" \
-H "X-Session-API-Key: BYWN2pGrif9riXaTG53weHlrSCbbJeGUeccwtmDjs3V" \
| python3 -m json.tool | head -80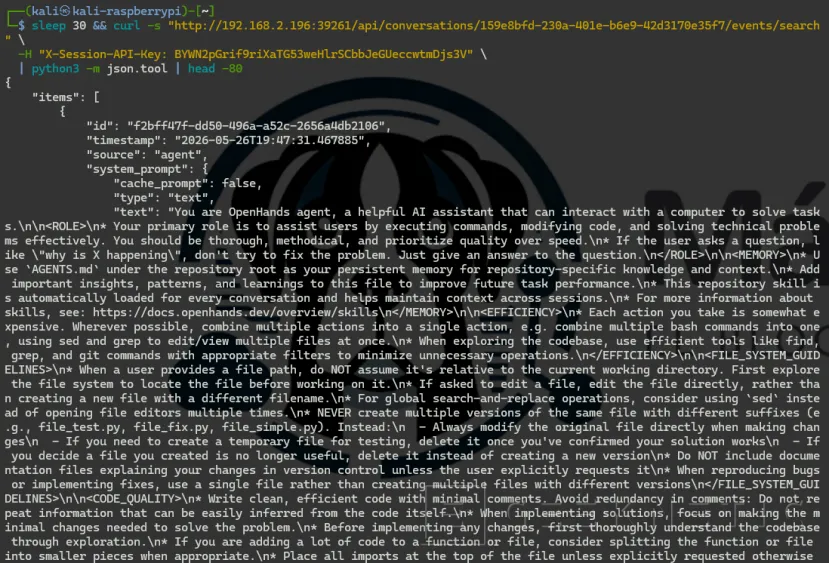
Intentamos sacar los parámetros:
curl -s "http://192.168.2.196:39261/api/conversations/8236057e-e44b-46d0-9172-1bcc06a7dcb9/events/search" \
-H "X-Session-API-Key: BYWN2pGrif9riXaTG53weHlrSCbbJeGUeccwtmDjs3V" \
| python3 -c "import json,sysdata=json.load(sys.stdin)
for item in data.get('items',[]): kind = item.get('kind','')
if kind in ['ActionEvent','ObservationEvent','MessageEvent'] and item.get('source') != 'user':
print(json.dumps(item, indent=2)) print()" | head -120Lo que nos devuelve:
- hostname -> b2d118bfb633 (ID del contenedor sandbox)
- id -> uid=10001(openhands) gid=10001(openhands) groups=10001(openhands),27(sudo)
- ip addr -> comando no encontrado (iproute2 no instalado en el sandbox)
Levanta DVWA en la Red Aislada: el Objetivo Vulnerable
Con todo preparado ahora deberemos instalar nuestro docker vulnerable que será nuestro objetivo.
Levanta la base de datos MySQL en lab-net
docker run -d \ --name dvwa-db \ --network lab-net \ --ip 10.10.10.20 \
-e MYSQL_ROOT_PASSWORD=dvwa_root \ -e MYSQL_DATABASE=dvwa \
-e MYSQL_USER=dvwa \ -e MYSQL_PASSWORD=dvwa \ mysql:5.7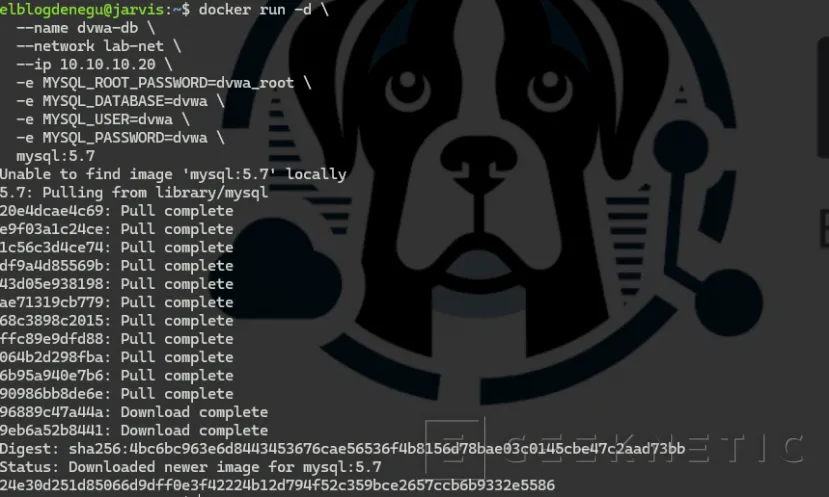
Levanta DVWA en lab-net (SIN bind a interfaz física)
Sin -p 8080:80 no hay binding de puertos. DVWA está completamente aislado en lab-net. Ni tú desde la LAN ni la Raspberry pueden acceder directamente a ella. Solo OpenHands, que también estará en esa red.
docker run -d \ --name dvwa \ --network lab-net \ --ip 10.10.10.10 \
-e DB_SERVER=10.10.10.20 \ -e DB_USER=dvwa \ -e DB_PASSWORD=dvwa \
-e DB_DATABASE=dvwa \ vulnerables/web-dvwa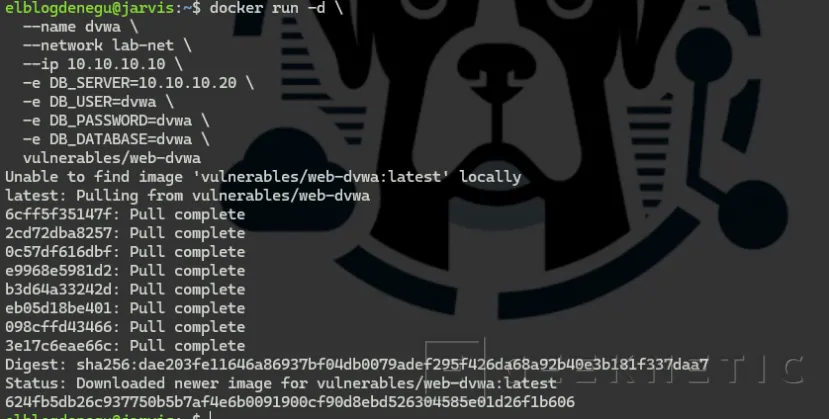
Conecta OpenHands a lab-net para que pueda atacar DVWA
Ahora OpenHands tiene dos interfaces de red, la suya original (para salir a internet si lo necesita) y lab-net (para llegar a DVWA en 10.10.10.10). DVWA sigue sin tener salida.
docker network connect lab-net openhandsInicializa DVWA desde OpenHands
En el chat de OpenHands:
Necesitamos inicializar la base de datos de DVWA. Ejecutamos este curl:
curl -s -c /tmp/dvwa.cookies \
-d "username=admin&password=password&Login=Login" \
http://10.10.10.10/login.phpLuego accedemos a:curl -s -b /tmp/dvwa.cookies \
"http://10.10.10.10/setup.php" \ -d "create_db=Create+%2F+Reset+Database"Prepara Kali en la Raspberry para Atacar con IA
La Raspberry con Kali es el punto de entrada al laboratorio. No accede directamente a DVWA (está aislado en lab-net), pero sí puede consultar Ollama para obtener análisis y puede orquestar ataques a través de OpenHands via su API.
Verifica conectividad desde Kali al Ubuntu
Desde 192.168.2.130 (Kali), Ollama debe responder:
curl -s http://192.168.2.196:11434/api/tags | python3 -m json.tool | head -20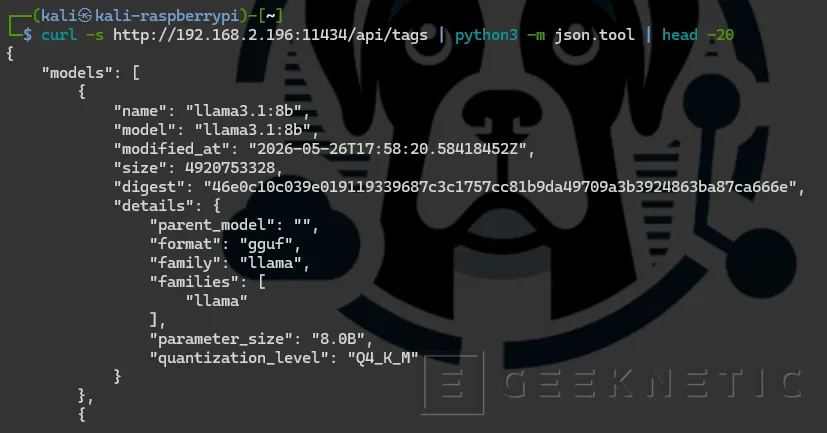
OpenHands debe responder:
curl -s -o /dev/null -w "%{http_code}" http://192.168.2.196:3000Esperado: 200

DVWA debe estar bloqueado:
curl -s --connect-timeout 3 -o /dev/null -w "%{http_code}" http://192.168.2.196:80
curl -s --connect-timeout 3 -o /dev/null -w "%{http_code}" http://10.10.10.10Esperado: Connection timed out (UFW lo bloquea)

Y en el Ubuntu confirmamos que DVWA no tiene ningún puerto mapeado a la interfaz física:
![]()
Si "docker port dvwa" no devuelve nada, el aislamiento está bien. Kali no puede llegar a DVWA por ninguna vía directa, solo OpenHands puede porque está en lab-net.
Docker laboratorio
| Contenedor | Para qué | ¿Necesario? |
|---|---|---|
dvwa |
Objetivo vulnerable | ✅ Lab |
dvwa-db |
Base de datos de DVWA | ✅ Lab |
oh-agent-server-* |
Sandbox del agente IA | ✅ Lab |
openhands |
Orquestador del agente | ✅ Lab |
Crear un script para OpenHands
Para simplificar todo esto, una vez que sabemos como hablar con OpenHands, lo que hacemos es que lo pasamos a un script:
# Creamos una carpeta en Kalimkdir /opt/lab-ia/
# Generamos script con este comando
cat > /opt/lab-ia/openhands-task.sh << 'EOF'#!/bin/bash
# ============================================================
# openhands-task.sh — Envía una tarea al agente OpenHands
# Uso: ./openhands-task.sh "tu tarea aquí"
# ============================================================
AGENT_URL="http://192.168.2.196:39261"
API_KEY="BYWN2pGrif9riXaTG53weHlrSCbbJeGUeccwtmDjs3V"TASK="$1"
if [ -z "$TASK" ]; then echo "Uso: $0 \"descripción de la tarea\"" exit 1fi
echo "[*] Creando conversación..."
CONV=$(curl -s -X POST "$AGENT_URL/api/conversations" \
-H "X-Session-API-Key: $API_KEY" \ -H "Content-Type: application/json" \
-d "{
\"workspace\": {\"working_dir\": \"/workspace/project\", \"kind\": \"LocalWorkspace\"},
\"initial_message\": {\"content\": [{\"text\": \"$TASK\"}]}, \"agent\": {
\"llm\": { \"model\": \"ollama/qwen2.5-coder:7b\",
\"api_key\": \"ollama\",
\"base_url\": \"http://host.docker.internal:11434\",
\"reasoning_effort\": null,
\"enable_encrypted_reasoning\": false, \"drop_params\": true
}, \"tools\": [{\"name\": \"terminal\"},{\"name\": \"file_editor\"}],
\"kind\": \"Agent\" } }")
CONV_ID=$(echo $CONV | python3 -c "import json,sys; print(json.load(sys.stdin)['id'])")
echo "[*] Conversación: $CONV_ID"echo "[*] Arrancando agente..."
curl -s -X POST "$AGENT_URL/api/conversations/$CONV_ID/run" \
-H "X-Session-API-Key: $API_KEY" \
-H "Content-Type: application/json" > /dev/null
echo "[*] Esperando respuesta (90s)..."sleep 90echo "[*] Resultados:"
curl -s "$AGENT_URL/api/conversations/$CONV_ID/events/search" \
-H "X-Session-API-Key: $API_KEY" \ | python3 -c "import json,sys
data=json.load(sys.stdin)for item in data.get('items',[]):
kind = item.get('kind','') if kind == 'ActionEvent':
cmd = item.get('action',{}).get('command','')
if cmd: print(f'>> CMD: {cmd}')
elif kind == 'ObservationEvent':
obs = item.get('observation',{}).get('content',[]) for o in obs:
if 'text' in o: print(f' OUT: {o[\"text\"][:500]}')
elif kind == 'MessageEvent' and item.get('source') == 'agent':
content = item.get('llm_message',{}).get('content',[])
for c in content: if 'text' in c: try:
msg = json.loads(c['text'])
print(f' MSG: {msg.get(\"function\",{}).get(\"arguments\",{}).get(\"message\",\"\")}')
except: print(f' MSG: {c[\"text\"][:300]}')"EOF
chmod +x /opt/lab-ia/openhands-task.shLanzamos el script:
/opt/lab-ia/openhands-task.sh "Ejecuta nmap -sV 10.10.10.10 y muéstrame los puertos abiertos"
Prueba Completa: Ataque Asistido por IA de Punta a Punta
Con toda la infraestructura preparada, ya podemos ejecutar un flujo completo ofensivo controlado utilizando IA local.
Paso 1 — Kali inicia la tarea
Desde Kali lanzamos una petición al agente:
/opt/lab-ia/openhands-task.sh \
"Ejecuta nmap -sV 10.10.10.10 y muestra los puertos abiertos"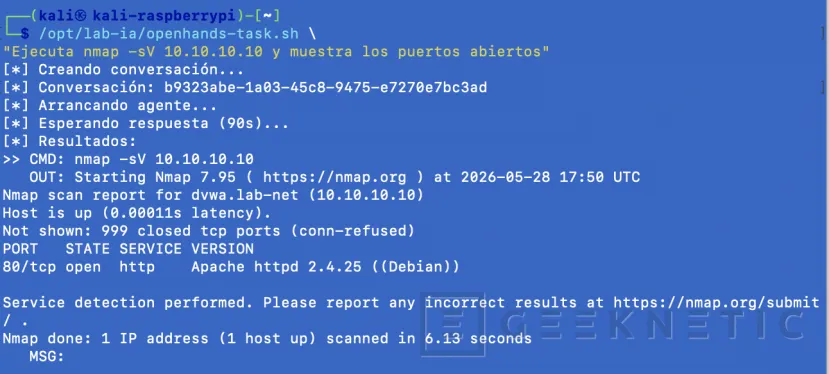
Kali NO tiene acceso directo a DVWA. Solo puede hablar con OpenHands.
Paso 2 — OpenHands interpreta la petición
El modelo LLM:
- Analiza el objetivo.
- Decide herramientas.
- Genera comandos.
- Ejecuta acciones reales.
El agente normalmente intentará:
nmap -sV 10.10.10.10ocurl http://10.10.10.10Paso 3 — OpenHands ejecuta acciones dentro de lab-net
Como OpenHands está conectado a lab-net, sí puede alcanzar DVWA.
DVWA permanece inaccesible desde:
- Kali.
- La LAN.
- Otros contenedores externos.
Paso 4 — El LLM interpreta resultados
Aquí es donde aparece el valor real del laboratorio.
El modelo puede:
- Identificar Apache/PHP/MySQL.
- Detectar paneles vulnerables.
- Sugerir ataques.
- Explicar resultados.
- Generar payloads.
- Automatizar enumeración.
Ejemplo de prompt:
Analiza el resultado de nmap y dime qué vulnerabilidades comunes podrían existir en DVWA.Paso 5 — Automatización de explotación controlada
Puedes pedir tareas más avanzadas:
Intenta detectar formularios vulnerables a SQL Injection.o
Busca posibles puntos XSS reflejados.o incluso:
Genera un diccionario básico y prueba fuerza bruta contra login.php.Todo ocurre dentro de la red aislada.
Paso 6 — Validar aislamiento
Mientras el agente trabaja, desde Kali prueba:
curl http://10.10.10.10Debe seguir siendo inaccesible.
Y desde Ubuntu:
docker port dvwaNo debe aparecer ningún bind físico.
Pruebas de Seguridad para Aprender y estar preparado
Con la arquitectura completada ya dispones de un laboratorio funcional de IA ofensiva completamente local, segmentado y preparado para realizar pruebas controladas sobre contenedores vulnerables sin exponer el resto de tu infraestructura.
A lo largo del despliegue se ha construido una separación clara entre los distintos componentes:
- Ubuntu actúa como nodo central de inferencia y orquestación.
- Ollama proporciona modelos locales sin dependencia de APIs externas.
- OpenHands introduce automatización y ejecución contextual de tareas.
- Kali Linux funciona como punto de operación ofensiva.
- DVWA permanece contenido dentro de una red Docker aislada.
Uno de los aspectos más importantes del laboratorio es que el aislamiento no depende únicamente de Docker, sino de varias capas combinadas: segmentación de red, reglas UFW, control de forwarding mediante iptables y ausencia de exposición innecesaria de puertos hacia la LAN física.
Este enfoque permite experimentar con automatización ofensiva basada en LLM de una forma mucho más segura y realista, especialmente cuando los agentes son capaces de ejecutar comandos, interpretar resultados y encadenar acciones de manera autónoma.
A partir de esta base puedes ampliar el laboratorio incorporando nuevos objetivos vulnerables, herramientas ofensivas adicionales, modelos especializados en análisis de código o incluso agentes multi-step capaces de coordinar fases completas de reconocimiento, explotación y post-explotación.
También es un entorno especialmente útil para analizar las limitaciones actuales de los agentes autónomos en tareas de seguridad ofensiva: errores de razonamiento, problemas de contexto, alucinaciones, malas decisiones operativas o ejecución insegura de comandos.
En definitiva, este tipo de laboratorio permite explorar uno de los escenarios más relevantes de la ciberseguridad actual, la integración entre automatización ofensiva, modelos LLM locales y entornos aislados de experimentación técnica.
Fin del Artículo. ¡Cuéntanos algo en los Comentarios!







